Image Aesthetic Assessment (IAA) predicts an image's overall aesthetic score, yet aesthetics is
shaped by multiple attributes whose relative importance varies across content and usage scenarios.
Under end-to-end training with only overall-score supervision, attribute signals are blended,
causing gradient conflict across samples dominated by different attributes —
gradients partially cancel, and systematic biases persist across diverse IAA models.
We propose AGREE, which learns attribute-specific subspaces and performs
sample-wise gradient routing based on perturbation-estimated sensitivity. It further reduces
feature coupling via semantic anchors and improves robustness through error-aware reweighting.
AGREE is plug-and-play for existing end-to-end IAA models, consistently
improving five benchmarks (AVA, LAPIS, AADB, TAD66K, PARA) across six representative baselines.
TL;DR
Shared-parameter IAA training induces gradient conflict across attribute-dominant
sample subsets. AGREE decouples attribute branches and routes updates per sample —
a plug-and-play module yielding up to +4.8% SRCC overall and
+38.5% SRCC on hard samples.
Optimization-oriented analysis showing that shared-parameter IAA training
induces persistent, attribute-related biases consistent across multiple baselines.
AGREE, a plug-and-play framework that adapts update allocation to
sample-specific attribute relevance without additional supervision or architectural changes.
Comprehensive experiments on 5 datasets × 6 baselines demonstrate
consistent improvements, with the largest gains concentrated on previously hard-to-optimize samples.
02 · Motivation
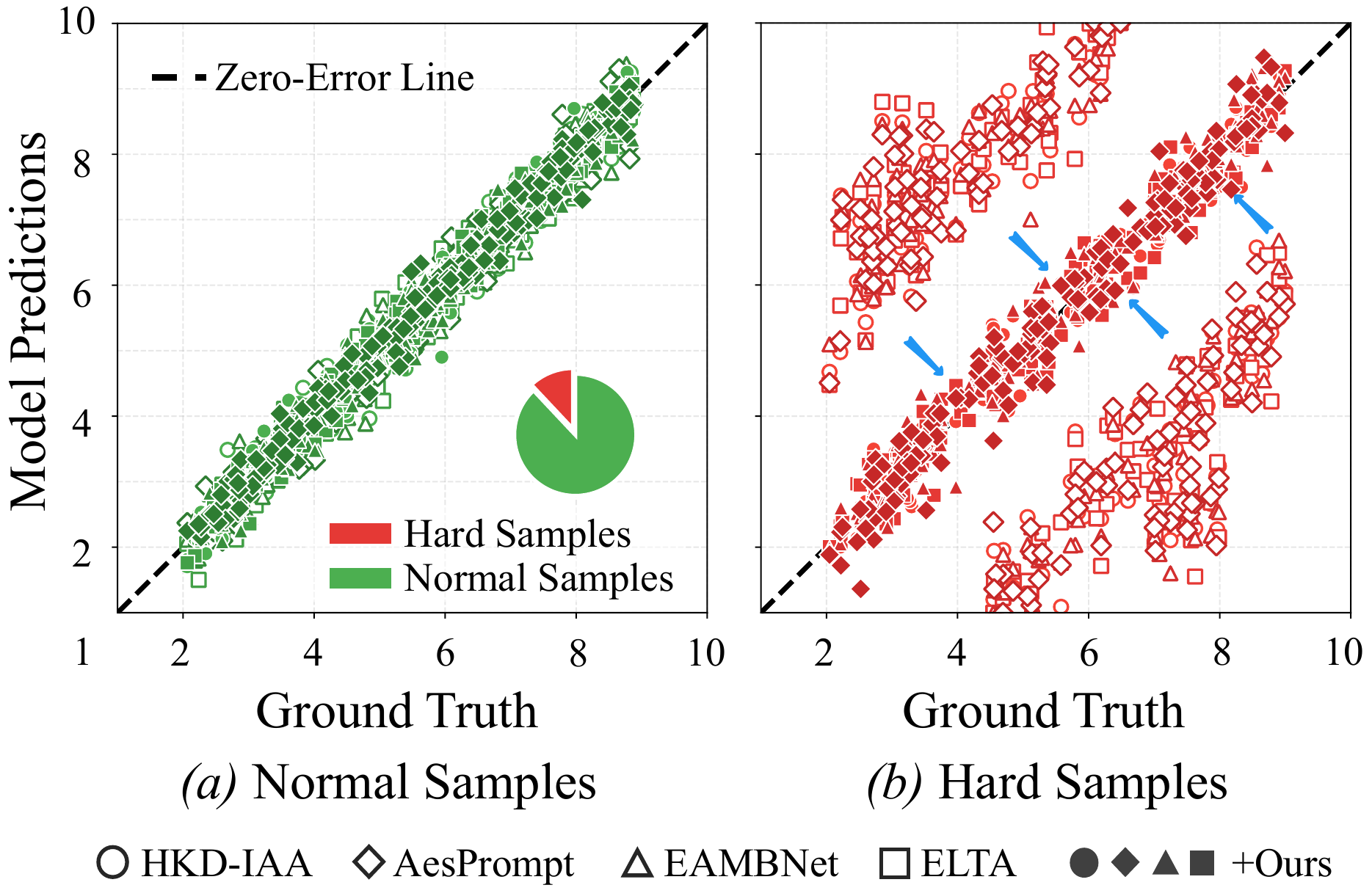
Different models, the same mistakes
We inspected prediction errors of several mainstream IAA methods and found a striking phenomenon:
while models achieve competitive average performance, they collectively fail on the same subset of
hard samples — forming stable error clusters in the prediction-label space.
This cross-model consistency suggests an optimization-level issue rather than random noise.
(a) Baseline models (hollow) achieve competitive performance on normal samples but collectively fail on hard samples; AGREE (filled) substantially reduces these shared errors.
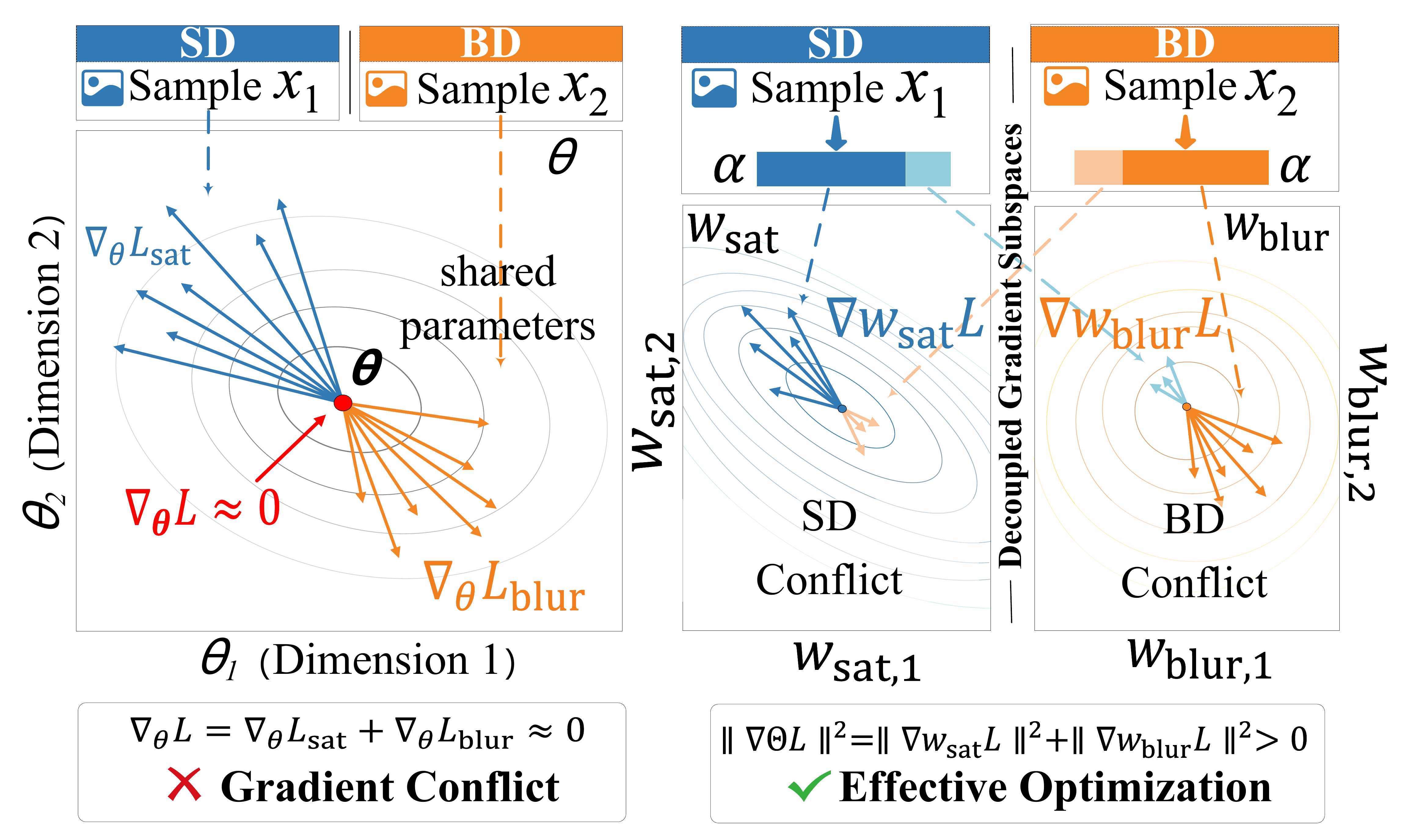
(b) Gradient conflict: subset gradients point in opposing directions on coupled parameters, partially canceling — leaving under-represented samples persistently hard to optimize.
03 · Method
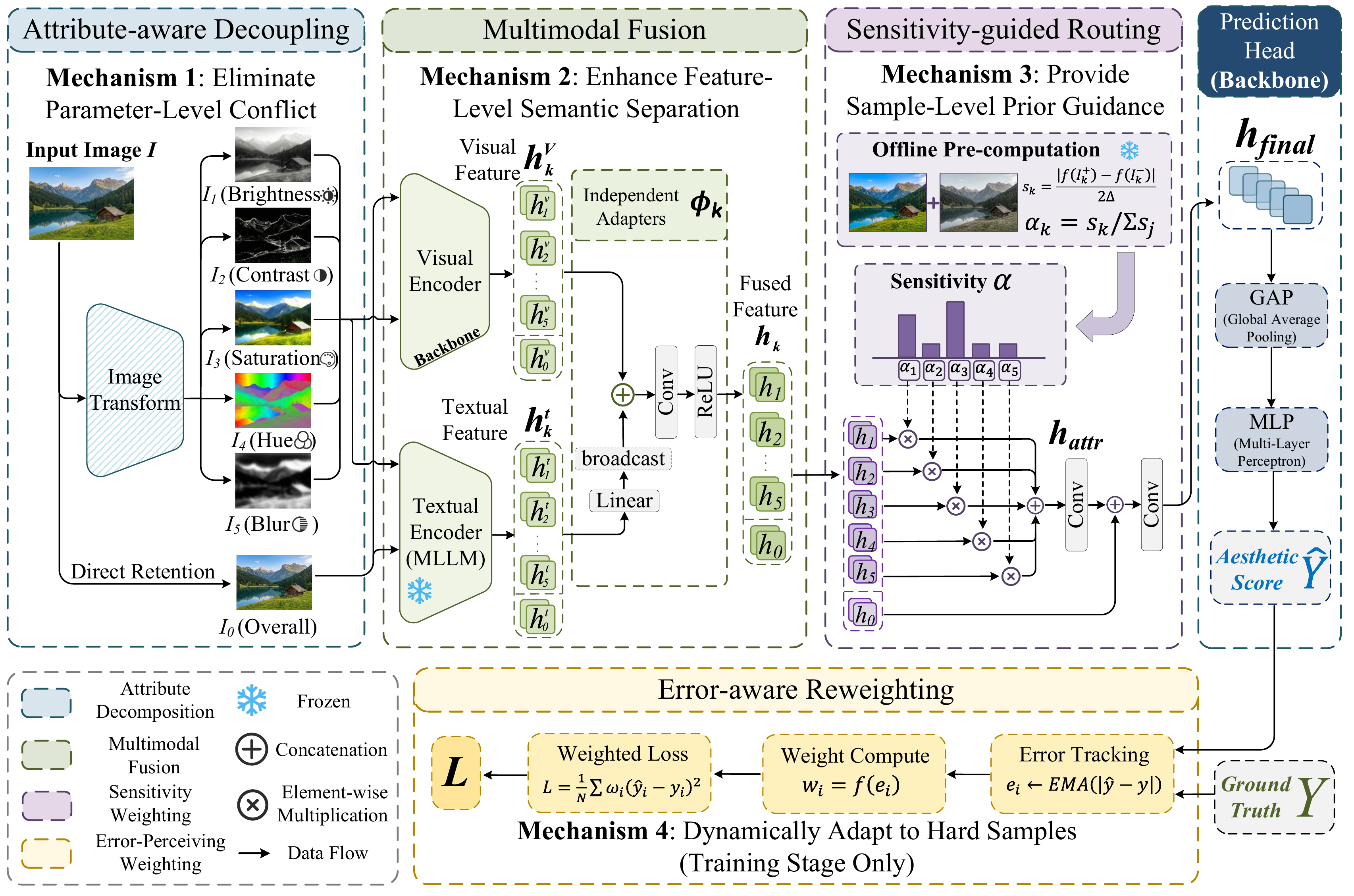
Four mechanisms to establish agreement
AGREE mitigates gradient conflict via four complementary mechanisms operating at the parameter,
feature, sample, and loss levels respectively — all without modifying the baseline architecture.
Overview of AGREE: a plug-and-play framework with four mechanisms — Attribute-aware
Decoupling, Multimodal Fusion with semantic anchors, Sensitivity-guided Routing, and
Error-aware Reweighting.
01 / Parameter
Attribute Decoupling
Decomposes the image into five attribute dimensions, modeled by independent adapter branches.
02 / Feature
Multimodal Fusion
Frozen LLaVA text anchors injected per branch provide semantic separation across attributes.
03 / Sample
Sensitivity Routing
Per-sample attribute sensitivity, computed offline via perturbation, guides feature fusion.
04 / Loss
Error-aware MSE
EMA-tracked errors dynamically upweight persistently hard samples during training.
04 · Results
State of the art across five benchmarks
+0%
SRCC · AVA
+0%
SRCC · LAPIS
+0%
SRCC · Hard
−0%
MAE · Hard
Method
AVA
LAPIS
PARA
AADB
TAD66K
SRCC
PLCC
SRCC
PLCC
SRCC
PLCC
SRCC
PLCC
SRCC
PLCC
TANet IJCAI'22
.684
.675
.694
.706
.815
.853
.564
.575
.425
.457
EAT MM'23
.752
.755
.802
.809
.891
.924
.601
.611
.476
.503
ELTA ICML'24
.698
.704
.686
.696
.826
.851
.592
.583
.413
.430
EAMB-Net TIM'24
.702
.707
.823
.825
.853
.876
.638
.640
.427
.428
HKD-IAA TMM'24
.753
.754
.781
.760
.867
.899
.671
.672
.395
.377
AesPrompt TMM'25
.724
.719
.792
.812
.875
.896
.562
.577
.452
.475
AGREE w/ EAT
.789
.791
.853
.853
.911
.940
.669
.678
.488
.511
AGREE w/ HKD-IAA
.761
.759
.859
.860
.879
.916
.682
.689
.432
.458
Δ Improvement
↑4.8%
↑4.8%
↑4.4%
↑4.2%
↑2.2%
↑1.7%
↑1.6%
↑2.5%
↑2.5%
↑1.6%
Bold = best, underline = second-best. AGREE integrated with two representative
baselines (EAT and HKD-IAA) jointly achieves SOTA across all five benchmarks.
05 · Plug-and-Play
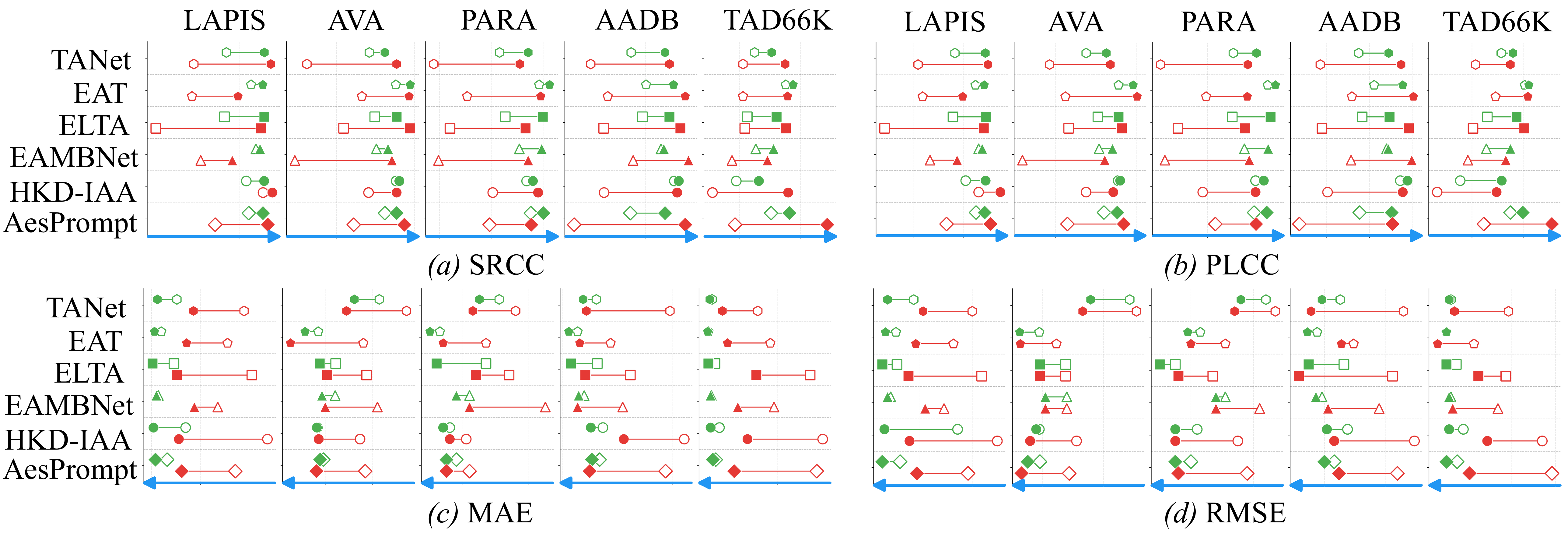
Consistent gains across six baselines
AGREE plugs into diverse IAA architectures, yielding average SRCC gains of 4.2%–12.6% across
datasets and improving hard samples by up to 38.5%. Even strong baselines
benefit substantially, confirming gains orthogonal to existing architectures.
Dumbbell plots across four metrics: (a) SRCC ↑ · (b) PLCC ↑ · (c) MAE ↓ · (d) RMSE ↓.
Each line connects baseline (hollow) to +AGREE (filled).
● overall ·
● hard samples.
Interactive: explore improvements across datasets & metrics
Switch dataset and metric — each row is one baseline; the bar shows how far +AGREE moves it from the baseline value.
Overall setHard subset○ baseline ● + AGREE
06 · Analysis
Gradient conflict, quantified and resolved
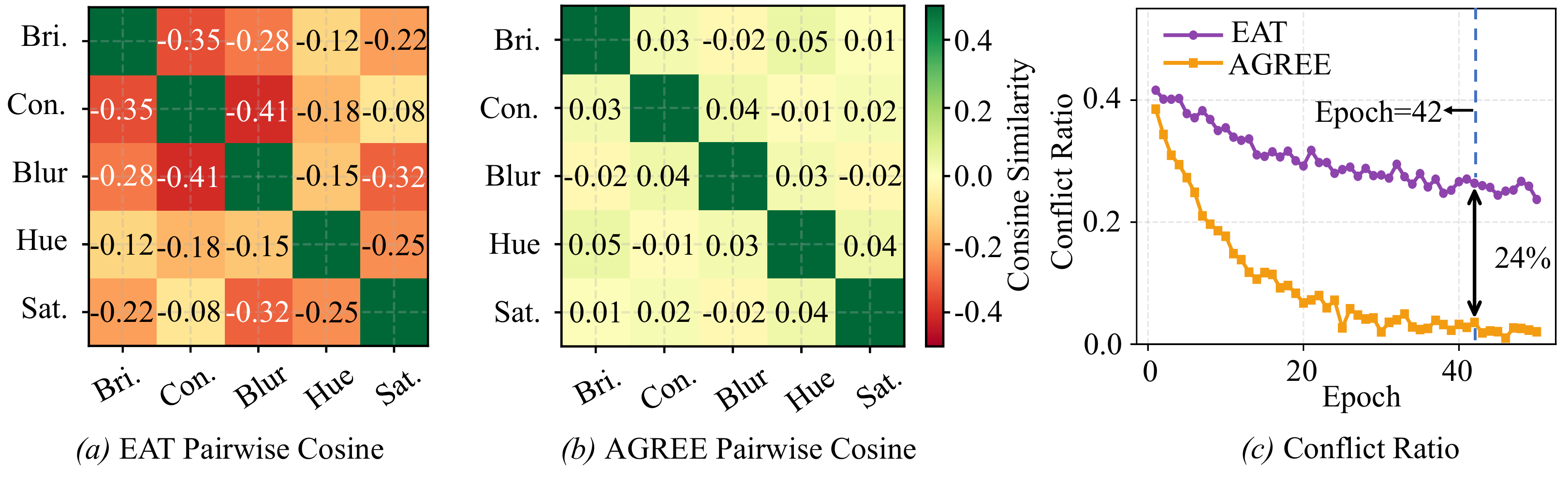
We quantitatively verify that AGREE eliminates inter-attribute gradient conflicts.
Cosine similarities across attribute branches drop to near zero (|cos|<0.05), and the
training-dynamic conflict ratio decreases by 24%, leading to smoother
optimization and faster convergence.
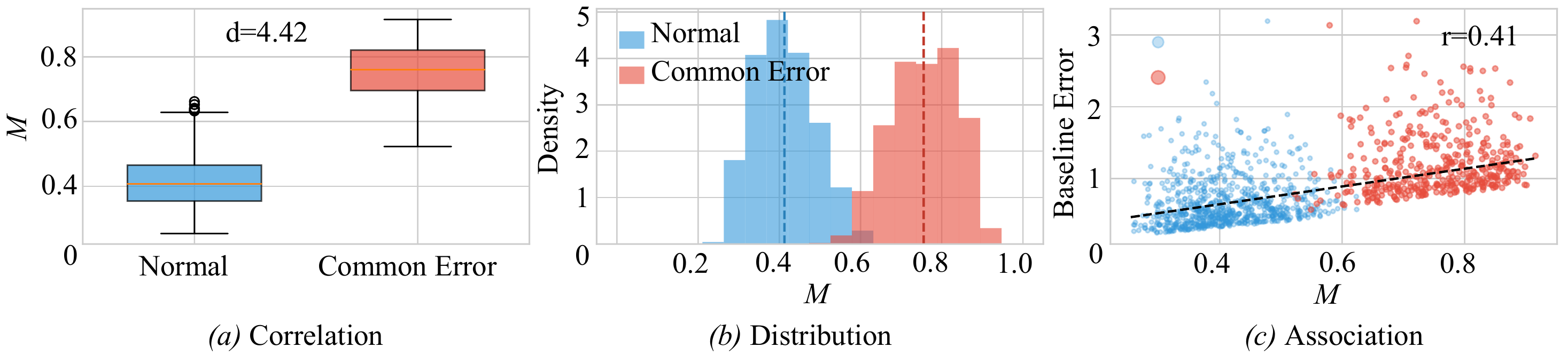
Hard samples are dominated by under-represented attributes.(a) The dominant-attribute marginalization M is significantly larger on common-error samples
(Cohen's d = 4.42). (b) Their M distribution shifts right and separates from normal samples.
(c)M positively correlates with baseline error (Pearson r = 0.41).
(a) Baseline EAT shows widespread negative cosine similarities between attribute pairs.
(b) AGREE keeps off-diagonal entries near zero. (c) AGREE reduces the conflict
ratio by 24% and stabilizes training dynamics.
07 · Ablation Playground
Toggle modules and see each contribution
AGREE comprises four mechanisms. Click the toggles below to enable/disable any combination —
results recompute live from the paper's ablation table (AVA, EAMB-Net backbone).
Decoupling
Multimodal Fusion
Sensitivity Routing
Error-aware MSE
SRCC ↑
.715
+0.013
PLCC ↑
.719
+0.012
MAE ↓
.411
−0.009
RMSE ↓
.527
−0.013
Baseline EAMB-Net (no toggles): SRCC .702 / PLCC .707 / MAE .420 / RMSE .540.
Δ shown relative to baseline.
08 · Citation
If our work helps yours
@inproceedings{wang2026agree,
title = {When Attributes Disagree: Gradient Conflict in Image Aesthetic Assessment},
author = {Wang, Ye and Dai, Maocai and Xie, Jiang and Bi, Xiuli and
Tao, Fei and Li, Xiao and Yu, Hong},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026}
}